阿里大神手把手教你畫技術架構圖 數據處理與存儲服務篇
在當今數據驅動的時代,數據處理與存儲服務構成了企業技術架構的基石。一個清晰、準確且富有洞察力的技術架構圖,不僅是團隊溝通的橋梁,更是系統設計與演進的藍圖。本文將以阿里資深架構師的視角,手把手帶你繪制一幅專業級的數據處理與存儲服務架構圖,并深入解析其核心要素與設計精髓。
第一步:明確繪圖目標與受眾
在動筆之前,首先要問自己:這張圖給誰看?是向業務方匯報數據流轉全景,還是與開發團隊討論技術選型細節?目標決定了圖的詳略與視角。對于數據處理與存儲服務,通常需要兼顧業務數據流與技術組件兩個維度。
第二步:確立核心分層與模塊
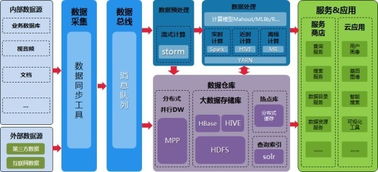
一個經典的數據處理與存儲架構通常可以抽象為以下幾層:
- 數據源層:明確數據從何而來。用圖標清晰標注各類源頭,如業務數據庫(MySQL、PostgreSQL)、日志文件、消息隊列(Kafka、RocketMQ)、第三方API等。這是整幅圖的起點。
- 數據采集與接入層:描繪數據如何被“搬進來”。使用統一的“管道”符號連接數據源與后續層,并標注關鍵組件,如Flume、Logstash用于日志采集,DataX、Sqoop用于批量同步,Canal用于數據庫增量訂閱。
- 數據處理與計算層:這是架構的核心“引擎區”。
- 流處理:用閃電符號或流線箭頭表示實時計算,標注Flink、Spark Streaming等框架及其上的實時ETL、風控規則計算等任務。
- 批處理:用齒輪或方塊表示離線計算,標注Hive、Spark、MaxCompute等平臺及其上的數據清洗、聚合、分析作業。
- 在此層,務必用虛線框或泳道圖區分開發、測試、生產環境。
- 數據存儲層:根據數據形態與服務目的,劃分不同的存儲區域,這是體現架構師功力的關鍵。
- 原始數據區/ODS層:存儲未經加工的原始數據,可用數據庫或HDFS圖標表示。
- 數據倉庫/DW層:存儲經過清洗、整合的主題域數據。用分層圖標(如DWD明細層、DWS匯總層)清晰展示。
- 數據湖:如果架構中包含,用湖泊圖標表示,用于存儲原始格式(如Parquet、ORC)的海量數據。
- 在線存儲:服務于在線應用的高性能存儲,如RDS(關系型)、Tair/Redis(緩存)、表格存儲(寬表)、OTS(有序)。用不同的數據庫圖標區分。
- 數據服務與應用層:數據價值最終在這里體現。描繪數據如何被消費,如通過統一數據服務API、BI報表工具(如Quick BI)、數據大屏、推薦/搜索系統等。
- 運維與治理層:作為支撐,貫穿上下。包括元數據管理、數據質量監控、任務調度(如Airflow、DolphinScheduler)、權限與安全管控。通常在圖的一側或底部以獨立模塊呈現。
第三步:選擇工具與繪圖規范
- 工具推薦:專業工具如Draw.io(免費、在線)、Visio、Lucidchart,或代碼繪圖工具PlantUML、Mermaid(適合版本管理)。阿里內部也廣泛使用這些工具或其定制版。
- 繪圖規范:
- 一致性:同一類組件使用相同或相似的圖形與顏色。例如,所有存儲用圓柱體,所有計算用矩形,所有隊列用管道。
- 流向清晰:使用帶箭頭的實線表示主要數據流,虛線表示控制流或低頻數據流。流向盡量從左到右、從下到上,符合閱讀習慣。
- 關鍵標注:在連接線上簡注數據協議(如HTTP、gRPC)、數據格式(如JSON、Avro)和同步頻率(實時、T+1)。在組件旁注明核心技術選型,如HBase vs Cassandra的選型原因。
- 突出重點:對核心鏈路、新引入組件或存在瓶頸的部分,使用醒目的顏色或外框加以強調。
第四步:繪制與迭代:一個阿里云參考示例
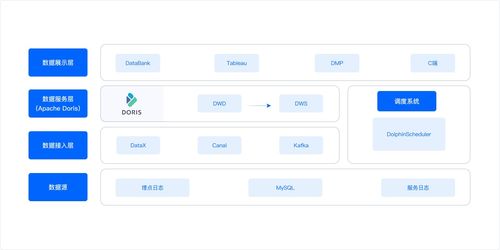
以構建一個典型的實時數據中臺存儲服務為例:
- 圖左側,畫出多個數據源(App日志、業務DB、IoT設備數據)。
- 數據通過DataHub(阿里云流數據總線)或Kafka統一接入,作為“數據高速公路”入口。
- 實時流進入Flink進行實時ETL、聚合計算;批數據通過DataWorks調度MaxCompute進行離線處理。兩條鏈路并行畫出。
- 處理后的結果數據,根據用途分流存儲:
- 需要實時查詢的維度表、用戶畫像,寫入Tair(緩存)和HBase(海量KV)。
- 需要復雜分析的歷史明細和聚合結果,寫入MaxCompute(數倉)和AnalyticDB(實時分析型數據庫)。
- 需要全文檢索的數據,寫入Elasticsearch。
- 上層通過API網關暴露統一的數據服務接口,供業務應用、BI報表調用。
- 整個流程由DataWorks進行元數據管理、任務調度與數據質量監控。
第五步:附注架構原則與設計思考
一幅優秀的架構圖不僅是組件的羅列,更應體現設計思想。在圖旁或文檔中,補充說明:
- 核心原則:如“分層解耦”、“實時離線一體”、“最終一致性”。
- 關鍵設計:如為什么選擇Lambda架構還是Kappa架構?冷熱數據分離策略是什么?
- 容災與高可用:數據備份、跨可用區部署、故障轉移機制如何在圖中體現。
- 成本與性能權衡:不同存儲選擇的成本效益分析。
###
繪制技術架構圖是一個不斷精煉和抽象的過程。從阿里眾多項目的實踐來看,一幅好的數據處理與存儲架構圖,應能讓人在3分鐘內把握系統全貌,理解數據從哪里來、如何加工、存于何處、誰去使用。它不僅是靜態的文檔,更應是隨著系統迭代而動態更新的“活地圖”。記住,清晰的架構圖背后,必然是清晰的架構思維。現在,打開你的繪圖工具,開始繪制屬于你自己的技術藍圖吧!
如若轉載,請注明出處:http://www.oilet.cn/product/37.html
更新時間:2026-03-19 05:03:49