AI大模型時代的數據處理與存儲服務 張亞勤的洞察與展望
在人工智能大模型快速發展的背景下,數據處理和存儲服務成為技術演進的核心支柱。張亞勤,作為人工智能領域的資深專家,強調了這一領域的關鍵作用。他指出,AI大模型的訓練和推理依賴于海量、高質量的數據,而高效的數據處理與存儲服務是確保模型性能、可擴展性和安全性的基礎。
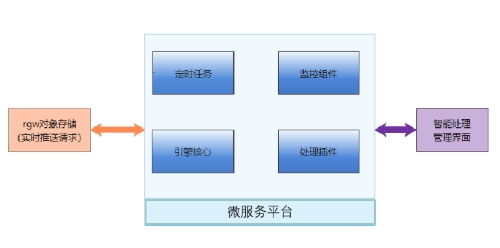
數據處理服務在大模型時代面臨著前所未有的挑戰。大模型需要從多源異構數據中提取特征,涉及數據清洗、標注、增強和聯邦學習等環節。張亞勤提到,傳統的數據處理方法已難以滿足需求,必須引入分布式計算、邊緣計算和實時流處理技術,以提升數據吞吐量和處理效率。數據隱私和合規性問題也日益突出,推動了對差分隱私、同態加密等前沿技術的應用。
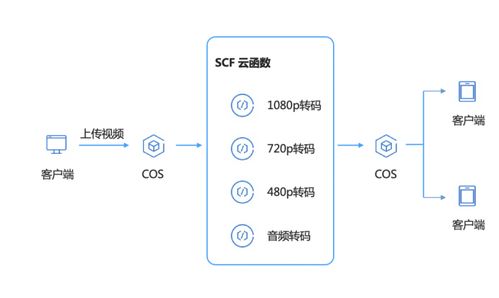
存儲服務在支撐大模型生命周期中扮演著關鍵角色。從原始數據到訓練中間結果,再到模型部署,存儲系統需具備高可用性、低延遲和高可擴展性。張亞勤強調,云原生存儲和對象存儲方案正成為主流,它們通過彈性資源分配,幫助企業降低總擁有成本。同時,隨著模型規模的擴大,對存儲介質的性能要求也在提升,例如采用NVMe和持久內存技術來加速數據訪問。
張亞勤認為,數據處理和存儲服務將進一步與AI技術融合,催生智能數據管理平臺。這些平臺將集成自動化數據治理、智能數據湖和跨云存儲能力,為企業和開發者提供端到端解決方案。他還呼吁行業加強合作,制定統一標準,以應對數據安全和倫理挑戰。
在AI大模型時代,數據處理和存儲服務不僅是技術基礎設施,更是創新驅動力的引擎。張亞勤的見解提醒我們,投資于這一領域,將助力全球AI生態的可持續發展。
如若轉載,請注明出處:http://www.oilet.cn/product/14.html
更新時間:2026-03-19 15:29:02